


🚀瀏覽完整的 Kaggle Notebook 內容:https://www.kaggle.com/yaojenkuo/analyzing-kaggle-survey-in-a-more-structured-way
關於 Kaggle Survey
Kaggle 從 2017 年起開始,每年年底、第四季左右都會寄送問卷給他們的用戶自由填答,在一段填寫時間之後,會將問卷回應發佈為一個競賽,今年的開放填答時間是 2021-09-01 至 2021-10-04、競賽的繳交期限是 2021-11-28。有興趣的讀者可以前往競賽頁面檢視:https://www.kaggle.com/c/kaggle-survey-2021,若是有寫作了 Kaggle Notebook 想要繳交作品,由於 Kaggle Survey 的競賽性質並不是預測資料輸出,因此透過 Google 表單來繳交:https://www.kaggle.com/page/2021-kaggle-survey-competition-submission-form
Kaggle Survey 2021 競賽主要的資料集是 kaggle_survey_2021_responses.csv,這是一個具有 51 個問題、369 個欄位以及 25,973 個觀測值的資料集。51 個問題中混雜著單選題(Multiple choice)與複選題(Multiple selection),單選題的回答用一個欄位做紀錄,複選題則會用多個欄位(個數不定,視該題的選項數有幾個而定)做紀錄,這也是資料集有 369 個欄位的緣故。對於剛拿到資料,正要進行探索分析(Exploratory Data Analysis, EDA)階段的參賽者而言,如果面對每一個不同的問題都需要手動選擇欄位、觀察分析並記錄結果,其實是一項蠻枯燥且乏味的任務。
寫作可重複使用的程式碼
熱愛使用 Jupyter Notebook 的資料分析師長久以來容易被詬病「無法寫作可重複使用的程式碼」,這除了跟筆記本設計為順序型程式設計(Procedural programming)習慣有關,還跟多數的資料分析師為跨領域背景、撰寫程式時沒有寫作函數、類別的習慣有關。因此,這次所上傳的筆記本中我並沒有如一般地去做資料的探索分析並將洞見說成故事,而是希望在資料分析中添加物件導向的風味,幫助參賽者能更簡便地去暸解、探索資料;我寫了一個類別 KaggleSurvey2021 並定義了三個主要的方法,也在方法中加入型別提示(Typing hints):
generate_question_table():這個方法能夠回傳可以讓參賽者對問題索引、問題內容與問題類型一目暸然的資料框。summarize_survey_response(question_index, order_by_value=True, show_value_counts=True):這個方法能夠依據參賽者所輸入的問題索引回傳該問題的聚合結果,更棒的是它能夠指定要依據數值排列(預設)或依據回覆排序(order_by_value=False)、也能夠指定要以計數回傳(預設)或以比率回傳(show_value_counts=False)。plot_survey_summary(question_index, horizontal=True, n=3):這個方法能夠依據參賽者所輸入的問題索引畫出該問題聚合的長條圖,更棒的是它能夠指定要繪畫適合顯示依數值排列的水平長條圖(預設)或要繪畫適合顯示依回覆文字排列的垂直長條圖,問題內容會標註在圖表標題,使用適合顯示依數值排列的水平長條圖時會自動將前 n 高(n 預設為 3)的長條用紅色標註。
簡單示範一下如何使用 KaggleSurvey2021 類別,透過有效的 kaggle_survey_2021_responses.csv 路徑建立類別的實例。
csv_file_path = "../input/kaggle-survey-2021/kaggle_survey_2021_responses.csv"
kaggle_survey = KaggleSurvey2021(csv_file_path)使用 generate_question_table() 方法建立問題資料框並且統計問題類型。
survey_question_table = kaggle_survey.generate_question_table()
n_questions = survey_question_table.shape[0]
question_summary = survey_question_table['question_type'].value_counts()
n_multiple_choice = question_summary['multiple choice']
n_multiple_selection = question_summary['multiple selection']
print(f"There are {n_multiple_choice} multiple choices and {n_multiple_selection} multiple selections among {n_questions} questions.")
## There are 20 multiple choices and 31 multiple selections among 51 questions.使用 summarize_survey_response(question_index, order_by_value=True, show_value_counts=True) 方法獲得所輸入問題索引的聚合摘要,指定參數 order_by_value=False 可以調整為依據回覆排序,指定參數 show_value_counts=False 可以調整回傳值為比率,適用於單選題。
kaggle_survey.summarize_survey_response("Q1", order_by_value=False)
kaggle_survey.summarize_survey_response("Q7")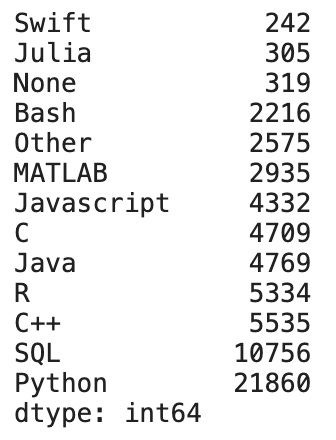
kaggle_survey.summarize_survey_response("Q8", show_value_counts=False)
使用 plot_survey_summary(question_index, horizontal=True, n=3) 方法獲得所輸入問題索引的長條圖,指定參數 horizontal=False 可以繪畫適合顯示依回覆文字排列的垂直長條圖,指定參數 n 將前 n 高的長條以紅色填滿強調。
kaggle_survey.plot_survey_summary("Q1", horizontal=False)
kaggle_survey.plot_survey_summary("Q7", n=4)
在示範了如何在資料分析中融入物件導向程式設計,藉此讓聚合或者作圖的程式碼也能夠具備「重複使用性」之後,這篇文章來到尾聲,希望讀者也和我一樣期待下一篇文章。如果讀者覺得這樣是有趣且方便的,是時候在你的下一個資料分析專案中撒上些物件導向的調味料!
對於這篇文章有什麼想法呢?喜歡😻、留言🙋♂️或者分享🙌
按下訂閱鈕透過電子郵件收到我的文章🎉