


什麼是梯度遞減
在約維安計畫:正規方程式一文中我們提到了正規方程式(normal equations),這是面對迴歸的機器學習任務時的函數生成方法,也是我們在機器學習系列文章中所學會的第一個學習演算法(learning algorithm)。在資料集給定特徵矩陣與目標向量,以及運用均方誤差(mean square error)作為效能評估的前提下,我們能夠計算權重向量,進而生成 h 函數。
不過,並非所有前提相同的問題以正規方程式求解權重向量都是最有效率的作法,原因是在正規方程式中,必須要求解轉置特徵矩陣和特徵矩陣相乘後的反矩陣,轉置特徵矩陣的外型為 (n, m),而特徵矩陣的外型為 (m, n),兩者相乘之後的矩陣外型為 (n, n)。
求解一個外型為 (n, n) 的反矩陣,標準的時間計算複雜度是大 O 符號 n 的立方 O(n^3),因此當特徵矩陣的變數增加 10 倍時,所需要的計算時間並不是增加 10 倍,而是增加 1000 倍,為此在因應 n 很大的狀況時,我們會改用第二個學習演算法:梯度遞減(gradient descent)。其中梯度(gradient)指的是在向量對函數的偏微分,對應導數(derivative)指的是純量對函數的偏微分。
梯度遞減指的是,在資料集給定特徵矩陣與目標向量,且效能評估的函數可以做最小化或最大化的前提下,我們能夠以多次迭代的方式優化權重向量,進而以優化過後的權重向量生成 h 函數。其中 w 是隨機生成的權重向量,J 函數是成本函數(cost function),也就是用來進行效能評估的函數,有時也寫做 L 函數即損失函數(loss function),而 epsilon 則是一個正的純量,稱作學習速率(learning rate),是一個決定優化幅度的正數純量。
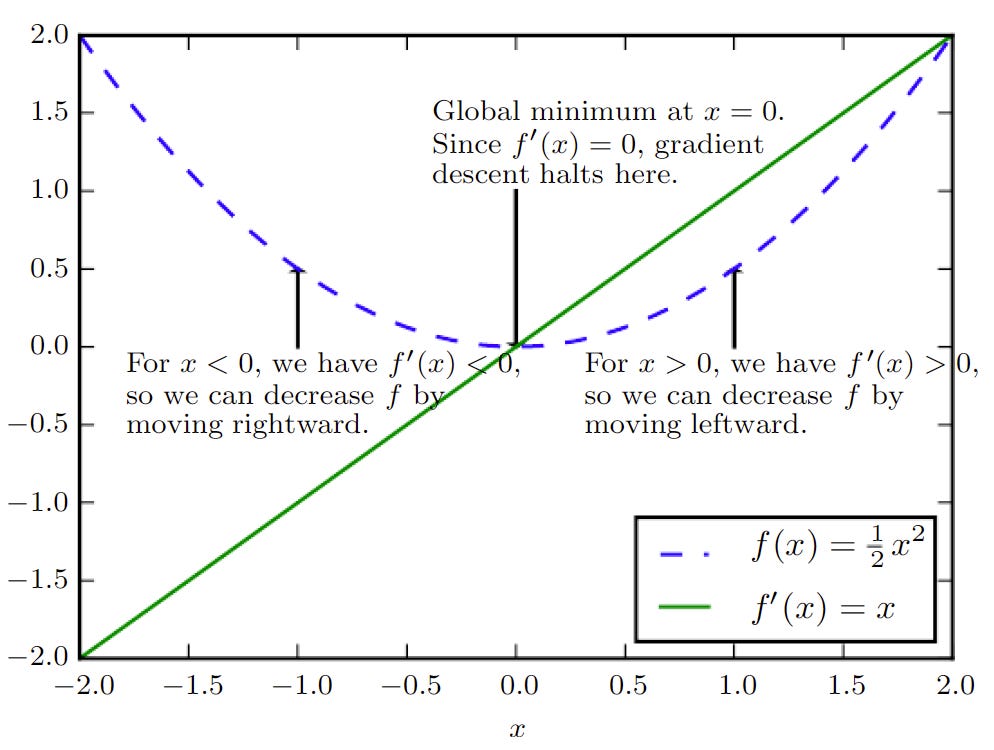
上圖中的藍色虛線描繪一個成本函數 f,綠色實線描繪該函數的導數,對於 x < 0 的部分導數為負,所以 x 會向右移動;對於 x > 0 的部分導數為正,所以 x 會向左移動;對於 x = 0 的部分導數為零,x 不移動。
效能評估
以均方誤差(mean square error)作為成本函數 J 來當例子,我們可以推導梯度的表示式如下。
因此,當以均方誤差作為成本函數時,我們可以將梯度遞減的泛型式表示如下。
以 Numpy 實作梯度遞減
成功推導出正規方程式之後,最後我們寫作一個類別 GradientDescent,以 Python 與 Numpy 模組實作,在給定適當資料集的特徵矩陣與目標向量,能夠迭代優化隨機生成的權重向量,進而生成 h 函數。實作過程中我們會用到 Numpy 模組的 np.transpose() 或 ndarray 的 T 屬性來生成轉置矩陣、np.dot() 或 ndarray 的 dot() 方法來計算向量與矩陣的相乘。
class GradientDescent:
def fit(self, X_train, y_train):
# ...
def predict(self, X_test):
# ...GradientDescent 類別的使用是以 fit() 方法生成權重向量,並以 predict() 方法生成預測。我們可以將 GradientDescent 類別應用在 Kaggle 的 House Prices 資料集,藉此來驗證它的可用性。
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
X_train = train["OverallQual"].values.reshape(-1, 1)
y_train = train["SalePrice"].values
X_test = test["OverallQual"].values.reshape(-1, 1)
gradient_descent = GradientDescent()
gradient_descent.fit(X_train, y_train)
y_pred = gradient_descent.predict(X_test)第四十二週約維安計畫:梯度遞減來到尾聲,希望您也和我一樣期待下一篇文章。對於這篇文章有什麼想法呢?喜歡😻、分享🙌、訂閱📨或者留言🙋♂️
約維安計畫學員專區
約維安計畫學員可以點選下列連結複製完整的內容與程式碼到自己的 Google Drive 之中。